Introduction
This is a new series where I’m documenting the entire process of building my 6th SaaS product.
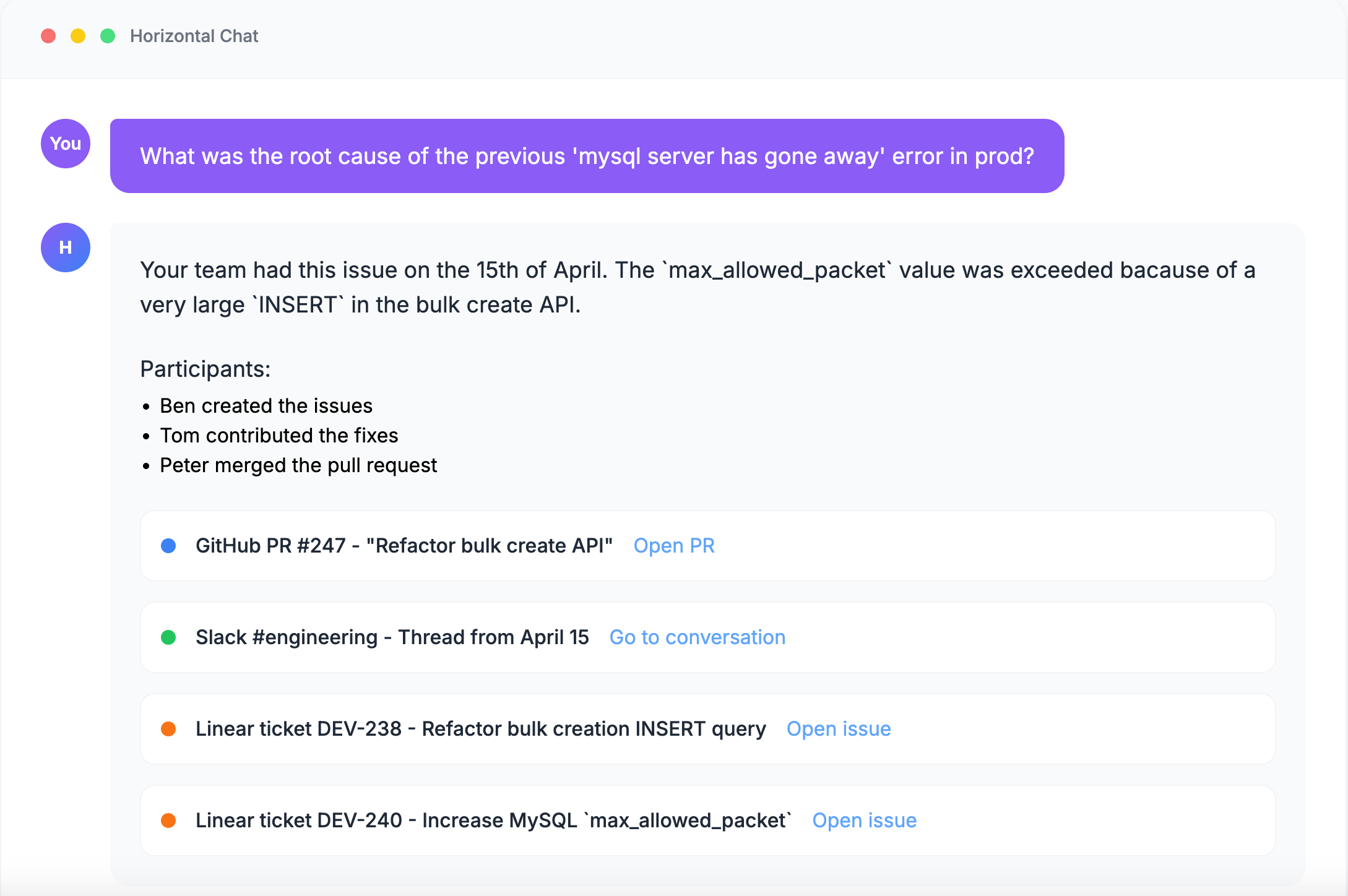
It’s an app that connects all the knowledge in your team and makes it super accessible:
You can read more about the idea in part 1.
It’s called Horizontal
Be honest, please:
Integration hell
In order to build something like this, first, I need to integrate tons of applications, including:
-
Gmail
-
Google Drive
-
Dropbox
-
Calendar
-
Notion
-
Trello
-
Linear
-
Slack
-
S3
-
GitHub
-
Jira
-
etc
This is what most companies use to handle product development, marketing, sales, engineering, support, etc. This is where the important information lives.
To be able to search through the content, I need to get it from these APIs and store it locally in my database.
For the MVP version, I’ll choose 3 or 4 of those and integrate their APIs into my app. I think I’ll start with these:
-
Drive
-
Slack
-
Linear or Jira
That’s already an annoying task:
-
Different auth methods
-
Different APIs (rest API, GraphQL, rpc)
-
Rate limits
-
Webhooks
-
etc
On top of that, I need to create some kind of abstraction that makes sense for all of those.
On top of that, I need to:
-
Get old content (using APIs)
-
Get new content near real-time (using webhooks)
This way, I can maintain an up-to-date representation of a team’s Drive folder, for example.
But that’s the easy part.
Now comes the hard part.
Indexing terabytes of data
Let’s focus on Google Drive for a minute. They offer:
-
15GB for free
-
100GB for $2
-
2TB for $10
If only a few dozen users try my app, that potentially means terabytes of data.
The exact numbers and statistics don’t matter that much. The bottom line is that it’s unmaintainable.
And besides Google Drive, there are still two or three other providers.
I don’t want to maintain a 10TB database in a solo project. And it’s not even a big number. 5 users with a $10 subscription can potentially have 10TB of Drive storage.
Managing this would be very hard and expensive.
But I need to store the content if I want to run searches on it, right?
Metadata indexing
One of the possible solutions to the storage problem is only indexing file metadata (such as name, path, etc) and a preview of the document. The preview can be the first 2KB of the text, or a 2KB summary of the entire document, for example.
This way, each document can be reduced to 2-5KBs. I can probably reduce the storage requirement by ~90%.
But of course, reducing a 5MB document to a 2KB summary means lots of information loss and poor quality. So this is probably not the best solution.
Selective indexing
I can prioritize files based on different criteria such as:
-
Size
-
Type
-
Last updated
Size-based selection
-
Fully indexing files < 10MB
-
Extract preview or summarize files < 100MB
-
Metadata-only for file > 100MB
Type-based selection
Another option is to prioritize files by type:
-
High priority: Google-native files (such as a Google Doc, spreadsheet, etc)
-
Mid priority: Office docs (.docx, .xlsx)
-
Low priority: images, videos, zips, etc
So the app would prioritize a Google Doc over a random video.
Recency bias
I can also check when the file was last updated/accessed and use this to prioritize files:
-
Full indexing: files modified in the last 30 days
-
Preview/summarization indexing: last 6 months
-
Metadata-only: older than 6 months
Obviously, there’s no right answer here. For example, an 8-month-old document will be very important when you want to gain knowledge about an 8-month-old decision.
I’ll probably use a smart combination of these.
Progressive indexing
I can do the whole sync process in phases. For example, after a user registers and authorizes Drive, here’s what I can do.
Immediate
-
Indexing all files for metadata
-
Extract content from recently modified/accessed Google-native files
These would happen in background jobs that will be processed as soon as possible, so the user will see some results quite quickly.
Later
-
Extract content from larger files
-
Extract content from older files
These would also happen in background jobs, but with lower priority. Maybe in a few hours or something like that, based on the traffic.
Hybrid storage
When discussing data storage, especially in large-scale systems and cloud environments, there are three important terms:
-
Hot storage
-
Warm storage
-
Cold storage
Hot storage
It’s designed for data that is accessed very frequently, requires extremely low latency, and high throughput. It’s the most expensive tier per gigabyte but offers the best performance.
It’s your database. In my case, it’s Postgres.
It can store:
-
Metadata and preview text for all files
-
Embeddings for semantic search (I’ll post a dedicated issue about this topic)
-
The full content of the most important files
Warm storage
It’s for data that is accessed less frequently than hot data but more often than cold data. It offers a balance between performance and cost.
In my case, it’s S3 (or DigitalOcean Spaces). I’ll use it as an extension to Postgres.
It can store:
-
The full content of the least recently accessed files
-
and/or the content of larger files
The Postgres DB will store the S3 links for files that are stored there.
Cold storage
It’s for data that is rarely accessed, if at all, but needs to be retained for long periods due to compliance, archival, or disaster recovery purposes. It’s the least expensive tier but has the highest latency for retrieval.
In my case, it’s going to be the Drive API.
Which is technically not a “storage” layer, but I wanted to include a chapter about cold storage.
For some files, I can just have a reference in my Postgres DB and send an API request on demand if needed.
As you can see, I have several challenges to solve.
Support
If you want, you can support Horizontal in different ways:
-
Join the project as a marketer
-
Join the project as a developer
-
Bring your team as beta testers
If you’re interested, drop me an email at martin@martinjoo.dev or book an appointment in my calendar here.
Computer Science Simplified
[crypto-donation-box type=”tabular” show-coin=”all”]




