Introduction
If you want to learn about Golang, you’ll pretty quickly run into its main selling points:
-
Simplicity
-
Easy concurrency
I agree with both of those, but as a PHP/javascript developer, understanding its concurrency model was a tiny bit harder than I expected (skill issues, I know).
A few months ago, I started writing a “cleanup” script for one of my side projects, and I realized this is the perfect script to showcase the basics of Golang concurrency.
The project was a code-running platform such as LeetCode. You are presented with a challenge, you write your code and submit it. It supports PHP, Javascript, Go, MySQL, and Redis (there are MySQL and Redis-related challenges). To execute your submission fast, it creates containers in advance. Instead of creating a container on the fly when you submit your code (which is very slow), it maintains a container pool. So at any given moment, there are (let’s say) 3 running PHP containers, 3 running node containers, etc.
For local development, I didn’t use Docker (skill issues, again), so there were dozens (if not hundreds) of containers on my laptop. On production, it uses a docker-in-docker image so there are only ReelCode-related containers on the host machine, and these containers run the container pool with hundreds of containers ready to execute your code.
So I needed a cleanup script that stops and removes these containers from my laptop. But if the script works sequentially it takes a very long time to run. If stopping and removing a container takes 1 second, it takes almost a minute to remove 50 of them.
Building a database engine
Just a month from now I’ll release a book – Building a database engine.
The whole thing is written in Golang.
It’s going to be available on the 15th of April. It discusses topics like:
-
Storage layer
-
Insert/Update/Delete/Select
-
Write Ahead Log (WAL) and fault tolerance
-
B-Tree indexes
-
Hash-based full-text indexes
-
Page-level caching with LRU
-
…and more
Check it out and pre-order to get the best price:

Sequential implementation
First, let’s see the basic implementation without go routines, so you can understand the basic program without getting lost in details.
To interact with Docker from a Go program we need to use the official Docker CLI:
package main
import "github.com/docker/docker/client"
func main() {
targetContainers := []string{
"mysql:9.0.1",
"php:8.3.11-cli-alpine3.20",
"node:22.9.0-alpine3.19",
"golang:1.23.0-alpine",
"redis:7.4.1-alpine3.20",
}
cli, err := client.NewClientWithOpts(
client.WithTLSClientConfigFromEnv(),
client.WithHostFromEnv(),
)
if err != nil {
log.Fatal(err)
}
}targetContainers simply contains the Docker images the script will remove (I mean, the containers that run these images). There are more sophisticated solutions, such as using labels, but this works just fine for me.
After that it creates a new Docker client. It reads Docker-related options from the environment. For example, client.WithHostFromEnv() reads the DOCKER_HOST variable from the environment.
Since this is the main function of the program (the entrypoint) I can exit or panic the app if there’s an error (log.Fatal will log and exit). Don’t do this in the inner layer of your app. Just return the error.
Next, we can get the list of running containers:
ctx := context.Background()
containers, err := cli.ContainerList(ctx, container.ListOptions{})
if err != nil {
log.Fatal(err)
}cli.ContainerList is the equivalent of docker ps
Context is not important for this program, but in general, it’s a very useful 1st party package. With context, you can implement timeouts, cancellations, etc. For example, you can crash the program if cli.ContainerList takes more than X seconds.
containers is a slice (array) of Container objects. A container has properties such as ID, Image, etc.
Now that we have a container list, we can loop through it and filter the ones we’re interested in:
for _, c := range containers {
if !slices.Contains(targetContainers, c.Image) {
continue
}
}If the given image is not a target, skip it. If it’s a target, stop and remove the container:
for _, c := range containers {
if !slices.Contains(targetContainers, c.Image) {
continue
}
err = cli.ContainerStop(ctx, c.ID, container.StopOptions{})
if err != nil {
errors = append(errors, err)
continue
}
err = cli.ContainerRemove(ctx, c.ID, container.RemoveOptions{})
if err != nil {
errors = append(errors, err)
continue
}
fmt.Printf("container %s (%s) stopped and removedn", c.ID, c.Image)
ids = append(ids, c.ID)
}If something goes wrong while stopping or removing a container I don’t want to stop the execution. It should continue, and remove as many containers as it can. If there are 100 containers and the 3rd one fails I want the program to continue and remove the other 97 containers. So instead of returning, the app just collects the errors in a slice. The slice is defined before the loop:
errors := make([]error, 0)
ids := make([]string, 0)
for _, c := range containers {
// ...
}It’s a slice of error with a predefined length of 0. If you don’t know the length in advance just use 0. There’s another slice called ids. It collects container IDs that were successfully stopped and removed.
Now, let’s test it:
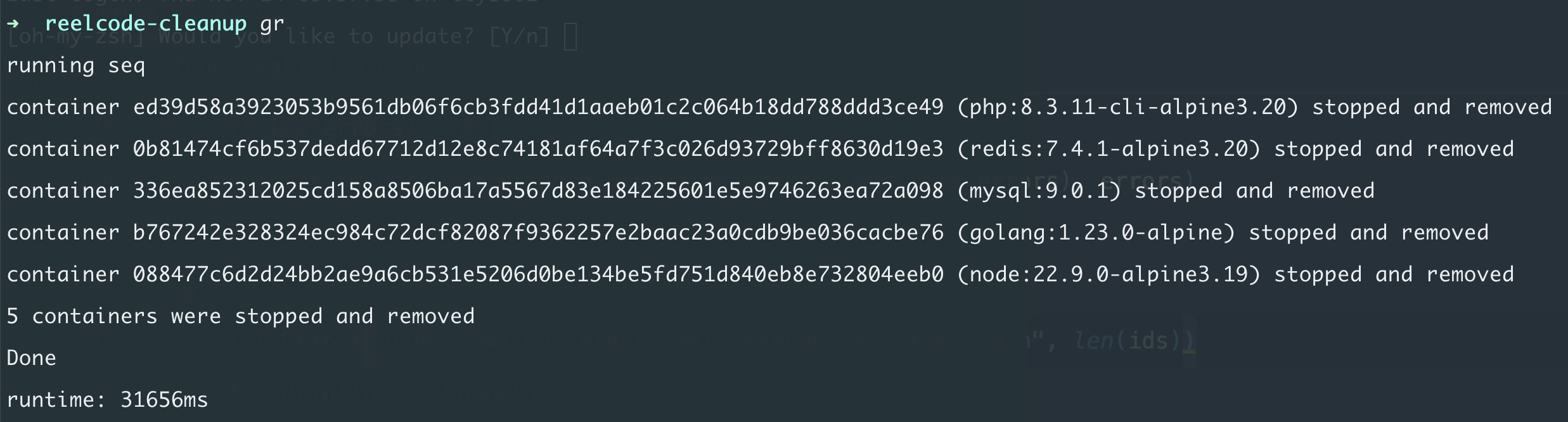
Stopping and removing 5 containers took 31 seconds. So 1 container took about 6 seconds.
We are wasting valuable time. While Docker is removing the PHP container, our program waits for 6 seconds. This is how any single-threaded language works such as PHP. It has some thread support but in the real world, we prefer solving these issues on the process level. This means dispatching queue jobs and running workers in separate processes (or servers). It works very well, and it’s often a requirement for a larger system (for example, processing requests in an async manner, decoupling services from each other using a message queue, etc).
However, for smaller tasks, such as removing containers faster, processing a big file in chunks, processing a very large table in chunks, etc, it is often too complex. Or at least, it makes the code more complex. But more importantly:
A simple programming problem becomes an architectural/infrastructural problem with queues, jobs, and workers involved.
And it comes with other disadvantages as well:
-
The code is more fragmented
-
Reviewing the code is a bit harder
-
Deployment is a bit more tricky
-
Rolling back a bad version becomes more risky
-
Workers can crash
-
The queue can run out of memory
-
Monitoring becomes more complex
-
etc, etc
These costs are often hidden until something goes wrong.
Goroutines
Goroutines are lightweight threads. Or green threads. A goroutine does not equal an OS thread. It’s an abstraction over it. One OS thread can run multiple goroutines. This is hidden from us and maintained by the Go runtime.
The sequential version works like this:
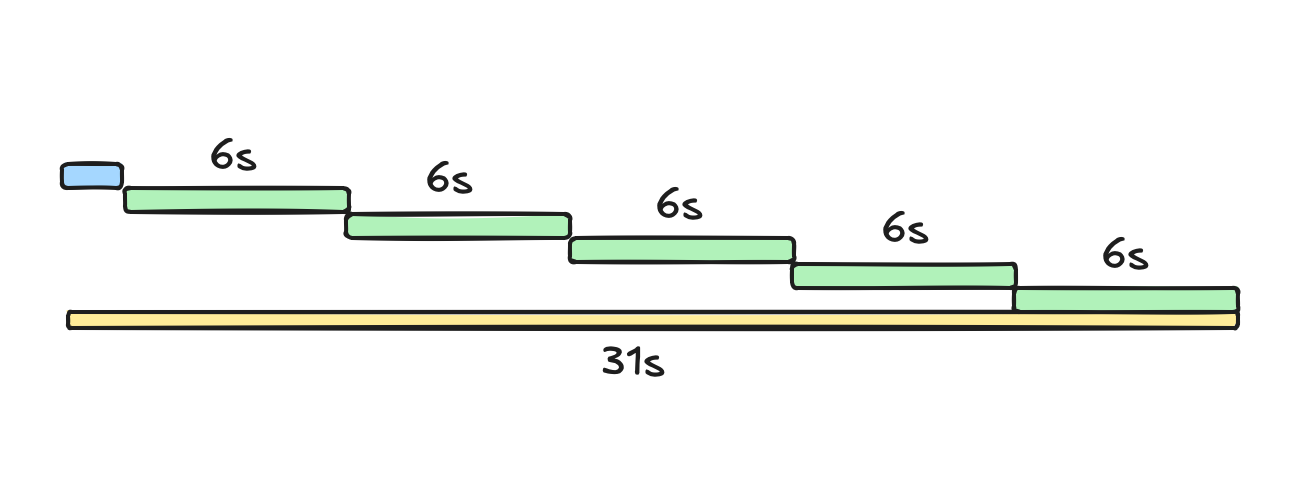
Each green box represents stopping and removing one container. The yellow line represents the entire runtime. The blue box at the beginning represents a ~1s timeframe that happens before the for loop (running docker ps, reading from the environment, creating a Docker client, etc).
Each green box is a “unit of work” that can run concurrently. They don’t depend on each other. The only dependency is the blue box (the result of docker ps) that happens before the loop.
So in this program, we can benefit the most by concurrently stopping and removing containers. Each goroutine handles a container. The execution flow should look something like this:

Of course, this is just an abstract representation. In the real world, we don’t know the exact execution flow of threads and goroutines. It might look something like this:
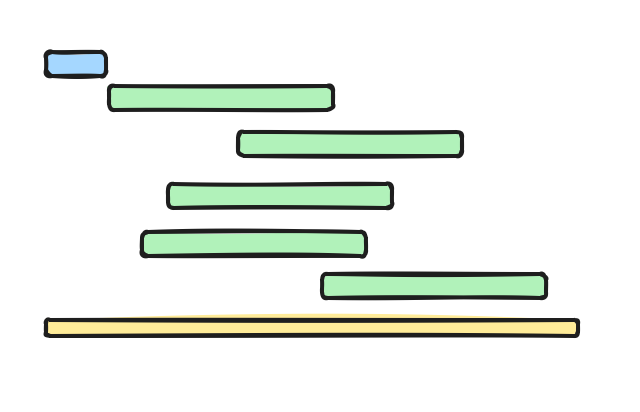
Still much more efficient than the sequential one.
To start a goroutine all you need is the go keyword:
func main() {
for i:=0; i<10; i++ {
go func() {
fmt.Println("this is a goroutine")
}()
}
}This loop spins up 10 goroutines. The function will run as a goroutine.
Of course, it doesn’t have to be an anonymous function. This works as well:
func main() {
for i:=0; i<10; i++ {
go myFunc()
}
}
func myFunc() {
fmt.Println("this is a goroutine")
}However, if you run this program, it won’t produce any output at all. It just starts and exits without printing anything to stdout.
Wait groups
There’s always a main thread when you run a Go program. This is your main function. It runs in its own thread.
When the main thread executes the for loop it creates 10 goroutines, but it exits immediately. It doesn’t wait for the goroutines to finish because we didn’t tell it to do so.
In order to wait for goroutines we can use a wait group:
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
fmt.Printf("goroutine %dn", i)
wg.Done()
}()
}
wg.Wait()
fmt.Println("all goroutines finished")
}In javascript, you would create the promises in advance and then use an await Promise.all() to wait for them.
In Golang, the approach is a bit different. Wait groups work like a “counter”:
-
In the loop, we increase the counter by calling
wg.Add(1).This tells the wait group that we have one more goroutine to wait for. -
In the goroutine, we decrease the counter by calling
wg.Done(). This tells the wait group that we have one less goroutine to wait for. -
After the loop,
wg.Wait()makes the main thread block and wait until the “counter” is 0 in the wait group.
This means that the last fmt.Println call only runs when all goroutines have finished.
The output looks like this:
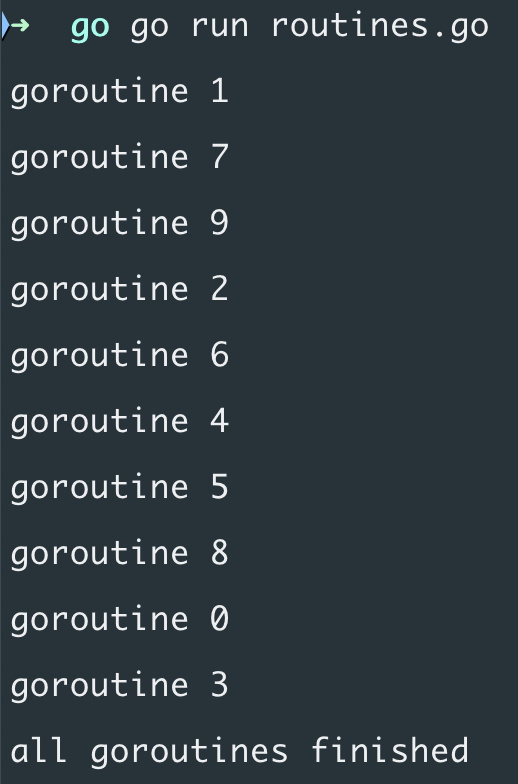
As you can see, the order is completely random, which is expected.
The above code snippet has some obvious “mistakes.” It works correctly, but it can be improved.
In the anonymous func we call wg.Done(). Imagine if the function is more complex, and it can fail for multiple reasons:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
err, val := someRiskyFunction()
if err != nil {
// do something with the error
wg.Done()
return
}
if val == "invalid_value" {
// do something with
wg.Done()
return
}
if val == "foo" {
// do something else and return
wg.Done()
return
}
// do something here with val and we're done
wg.Done()
}()
}
wg.Wait()
fmt.Println("all goroutines finished")
}In every branch, wg.Done() has to be called. This is a very fragile situation because it’s easy to forget about. And if you forget one of them, wg.Wait() will never finish, so you just crash your app. It’s dangerous.
Fortunately, Golang offers the defer keyword:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
err, val := someRiskyFunction()
if err != nil {
// do something with the error
return
}
if val == "invalid_value" {
// do something
return
}
if val == "foo" {
// do something else and return
return
}
// do something here with val and we're done
}()
}
wg.Wait()
fmt.Println("all goroutines finished")
}A deferred function (wg.Done() in this case) will execute when the function returns. No matter if the execution flow goes into the err != nil branch or the val == “invalid_value” branch, wg.Done() will always run as the last step of the function. This is a very useful mechanism and it can be used to:
-
Closing resources (files, for example)
-
Handling wait groups
-
Unlocking mutexes. This is also a crucial use case. We’re going to discuss it in a minute.
-
Seeking back files. I’m writing a database storage engine, and there are lots of file-handling functions. For example, it has a function that searches for something in the table file (the position of a 4KB page where the first record is stored). After it’s done it seeks the file back to the original position, so the caller function doesn’t have to worry about that.
-
Connection pools. In another article, we built a load balancer that uses a connection pool. A deferred function is the perfect place to put back the given connection into the pool after it is not needed anymore. I’m also working on ReelCode which is a code execution platform such as LeetCode. It uses a container pool to execute your code (so it doesn’t have to create a Docker container on the fly which is super slow). After your code is executed the container can be pushed back into the container pool. Once again, a deferred function is the best way to do that.
-
Closing TCP or HTTP connections
defer is an awesome mechanism to make your app more robust and safe.
So using defer is crucial when working with wait groups:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
fmt.Printf("goroutine %dn", i)
}()
}
wg.Wait()
fmt.Println("all goroutines finished")
}The other mistake in this snippet is the usage of wg. The main function declares it and the goroutines use it. This is not good for one obvious reason:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go myFunc()
}
wg.Wait()
fmt.Println("all goroutines finished")
}An antonym function can use the variable wg but of course myFunc cannot. Goroutines should accept a wait group as an argument, even if they are anonymous:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("goroutine %dn", i)
}(&wg)
}
wg.Wait()
fmt.Println("all goroutines finished")
}Now the anonymous function accepts a pointer to a wait group and we pass it as &wg. Why a pointer?
Let’s try a simple variable:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(wg sync.WaitGroup) {
defer wg.Done()
fmt.Printf("goroutine %dn", i)
}(wg)
}
wg.Wait()
fmt.Println("all goroutines finished")
}The output is:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [semacquire]:
sync.runtime_Semacquire(0x140000021c0?)
/usr/local/go/src/runtime/sema.go:71 +0x2c
sync.(*WaitGroup).Wait(0x1400000e0d0)
/usr/local/go/src/sync/waitgroup.go:118 +0x74
main.main()
/Users/joomartin/code/go/routines.go:17 +0x100
exit status 2This is a deadlock. It means we wait for something that will never happen.
This is where knowing how memory works can be very useful.
Each goroutine has its own stack. When you pass the WaitGroup by value it is copied to the stack. So each goroutine has its own local WaitGroup. When wg.Done() is called it has no effect outside of the anonymous function’s scope. It decrements the value of a WaitGroup that lives in the stack and gets destroyed when the function returns.
If you’re not sure about what is the stack and the heap check out this article. This whole concept is language agnostic and works very similarly in mainstream languages:
So each goroutine decrements its own copy of WaitGroup. This means that wg.Wait() in the main thread will wait forever (since it blocks the execution until it reaches zero, which never happens). Because its value is never decremented.
The Go runtime is smart, and it has a deadlock detector. It detects that each goroutine has finished and the main thread is blocked forever.
It is blocked and there’s no way to become unblocked.
So the runtime panics with a deadlock message.
The fix is a pointer as I already hinted:
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("goroutine %dn", i)
}(&wg)
}
wg.Wait()
fmt.Println("all goroutines finished")
}Now wg is allocated in the heap and each goroutine accepts a pointer that points to the same address. This way, incrementing, and decrementing work as expected.
Once again, if you’re not sure about stack vs heap, pointer vs variable check out my article about memory.
Channels
The next question is: how does a goroutine “return” a value? There’s no return value since it runs as a separate thread. Just like there’s no return value when you use a queue job.
Channels can be used to communicate between goroutines. First, let’s find out how they work, and then we can understand what’s happening under the hood:
resCh := make(chan int, 10)This creates a buffered channel that can hold a maximum of 10 integer values. If you have 10 goroutines and each produces a number, a channel like this can be used to store the results. For now, you can imagine a channel as an array or queue.
This is how you can send a value to the channel:
resCh <- 5To read all the values from a buffered channel, a for loop can be used:
for v := range resCh {
fmt.Prinln(v)
}By knowing these things, we can extend the previous example:
func main() {
var wg sync.WaitGroup
resCh := make(chan int, 10)
for i := 0; i < 10; i++ {
wg.Add(1)
go func(wg *sync.WaitGroup, resCh chan int) {
defer wg.Done()
fmt.Printf("goroutine %dn", i)
resCh <- i * 2
}(&wg, resCh)
}
wg.Wait()
close(resCh)
fmt.Println("all goroutines finished")
for v := range resCh {
fmt.Println(v)
}
}In the for loop we pass the channel into the callback function so each goroutine can send values to it. Channels have to be closed with the close() function just like files.
There are a few important things to understand before you start using channels.
Memory allocation
Channels are heap-allocated. resCh lives inside the heap and can be shared between function calls. make() returns a pointer to it.
The whole process (your program) gets one heap area. So the heap is “shared” across goroutines. This is why we can pass a pointer to a heap-allocated object.
You can imagine it like this:
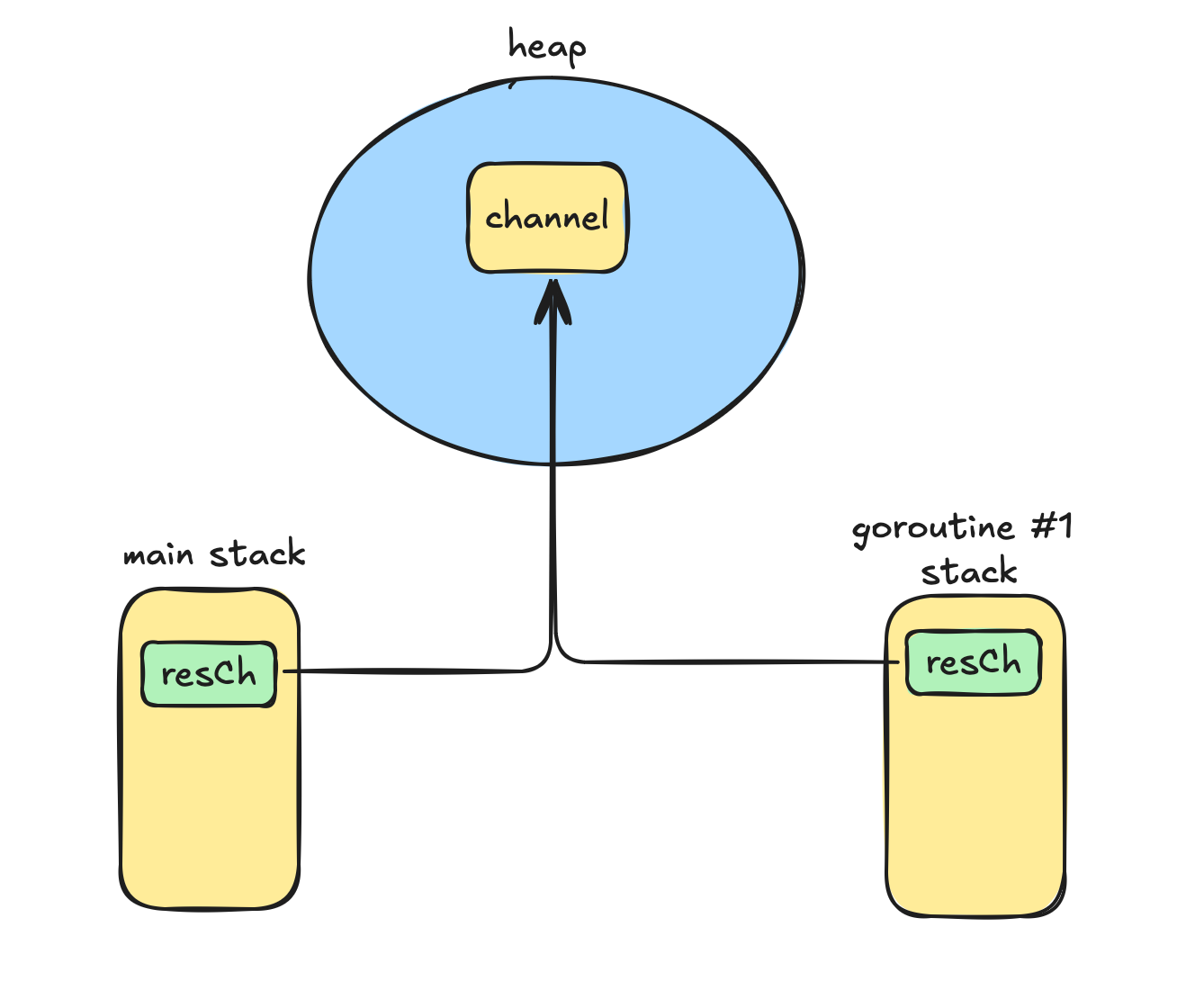
The channel instance lives in the heap, and resCh is just a pointer that can be used in goroutines.
Channel data structure
Earlier I said, you can imagine a channel as an array. It was a lie.
A channel is a struct. It’s an hchan struct, that looks like this:
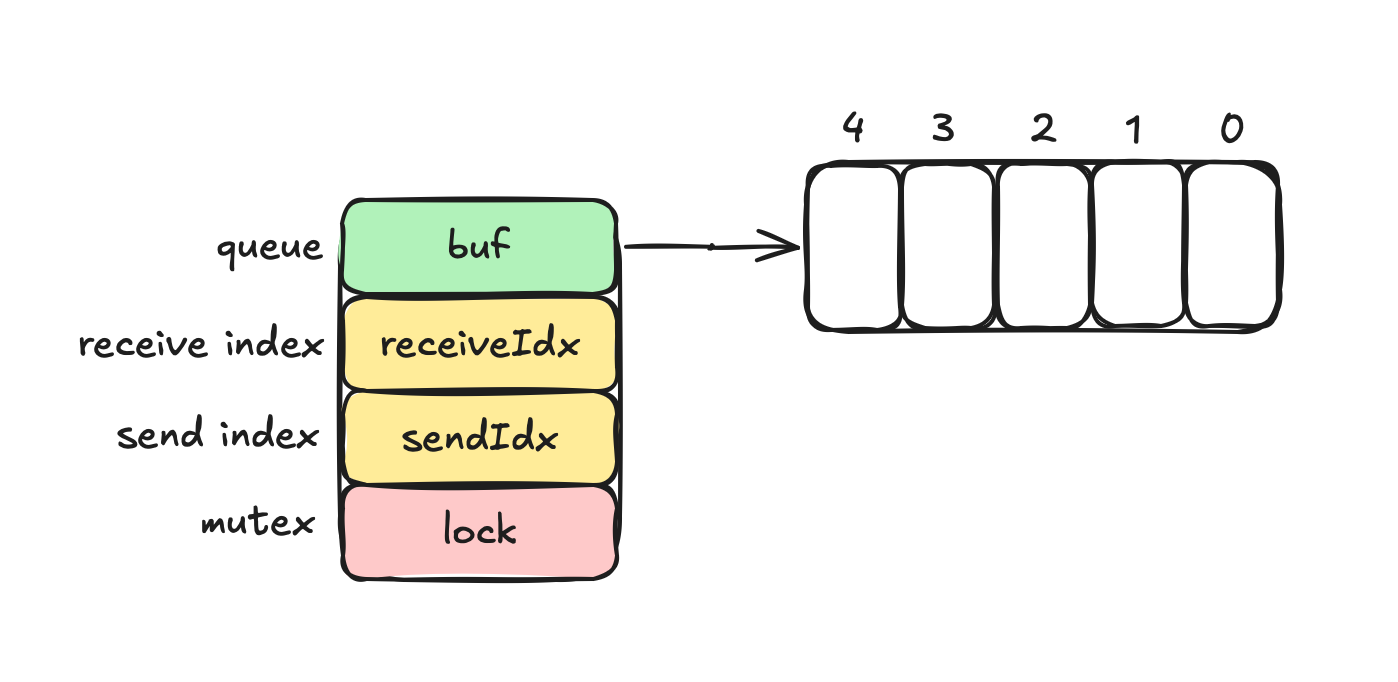
It’s a thread-safe FIFO queue. The above image shows a buffered channel with a capacity of 5:
resCh := make(chan int, 5)buf is the actual slice that stores the data. receiveIdx and sendIdx are integers that help coordinate things when you send or receive a value from or into the channel. They are counters. And finally, lock is a mutex that makes everything thread-safe. We’re gonna talk about mutexes a little bit later.
What happens when you send a value to the channel with
resCh <- 5-
First, it acquires a lock on the channel. As I said, we’re gonna talk about it later. But a simple explanation is: no one else can send or receive values from or to the channel until this operation is finished.
-
Then it performs an enqueue on the queue. It places the value at the beginning of the queue. It’s important to note that it performs a memory copy. When you send the value 5 it copies the bytes and puts them into the queue. In a minute, you’ll see why this step is important.
-
Finally, it releases the lock so other threads can use the channel for reading or writing.
When you receive a value from the channel, the following happens:
-
It acquires a lock
-
Performs a dequeue operation (which is also a memory copy)
-
Releases the lock
I said it’s important that it performs a memory copy. The reason is this:
Do not communicate by sharing memory. Instead, share memory by communicating.
– The Go blog, and also Effective Go
In this model, there’s no shared memory across goroutines. Only the channel is shared. Traditionally, multi-threading required sharing memory, sharing variables, objects, etc across threads and it’s a source of deadlocks, race conditions, and very hard to find bugs. Using channels makes everything simple.
What happens when the channel is full?
Given a channel with a capacity of 3:
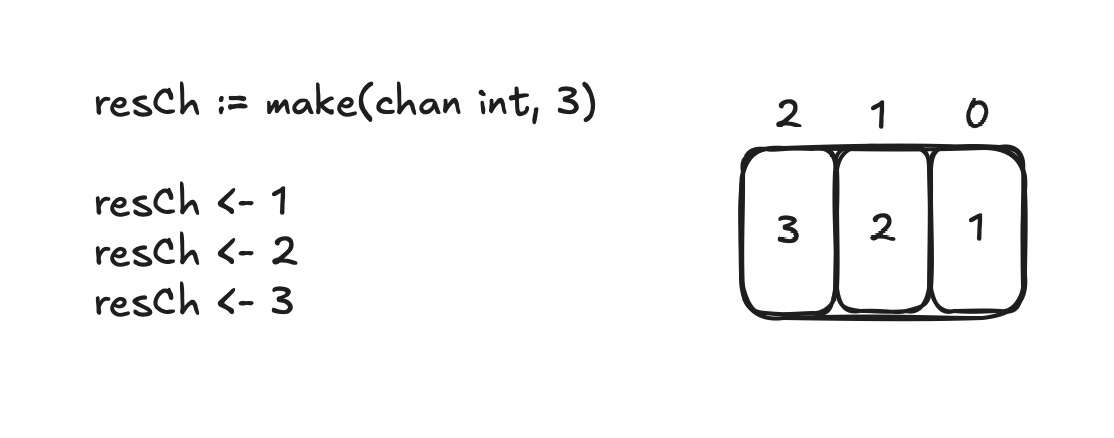
Let’s assume no one is receiving values from the channel. If you now try to send another value, the goroutine (remember, main is also a goroutine) will pause. It will resume, once the channel has enough space to store the next value. So channels can block the execution of a thread.
Under the hood, the hchan struct stores waiting receivers and senders as well in a queue. So when the channel has an empty slot again it knows which goroutine to resume.
Earlier I said that a goroutine is a lightweight, or green thread. This means one OS thread can execute many goroutines. Now that we understand that a channel can block a goroutine we also understand that it won’t block the entire OS thread actually. It only blocks your goroutine. This is great, because your web server, your background worker, and your MySQL database can still use the same amount of threads.
Handling errors
Now we understand how to handle “return values.” But what about errors? Since errors are values in Golang, we can handle them the same way. We can maintain a channel for results and another one for errors.
Going back to the original Docker container cleanup example:
var wg sync.WaitGroup
errChan := make(chan error, len(containers))
resChan := make(chan string, len(containers))
for _, c := range containers {
wg.Add(1)
go func(c Container, wg *sync.WaitGroup, errChan chan error, resChan chan string) {
defer wg.Done()
if !slices.Contains(targetContainers, c.Image) {
return
}
err = cli.ContainerStop(ctx, c.ID, container.StopOptions{})
if err != nil {
errChan <- err
return
}
err = cli.ContainerRemove(ctx, c.ID, container.RemoveOptions{})
if err != nil {
errChan <- err
return
}
fmt.Printf("%s (%s) stopped and removedn", c.ID, c.Image)
resChan <- c.ID
}(c, &wg, errChan, resChan)
}When something goes wrong, instead of returning the error it sends it to a channel:
errChan <- errIf everything goes well, it sends the result to another channel:
resChan <- c.IDBoth channels have a capacity of len(containers). You can’t have more errors or results than this.
I assume Golang is not your first language. I don’t like the word idiomatic (mainly because I’m not a native English speaker and I always think it means “idiot”) but it is used very often in the Go community.
The idiomatic way of naming variables is this:
errCh
resCh
errChan
resChan
wg
r
wNot this:
errorChannel
resultChannel
waitGroup
reader
writerYou can read more about it here and here.
Going back to the example. After, the loop, we can collect the errors from the channel into an array and we can do anything we want:
wg.Wait()
close(errChan)
close(resChan)
var errs []error
for err := range errChan {
errs = append(errs, err)
}
if len(errs) > 0 {
fmt.Printf("encountered %d errors: %v", len(errs), errs)
}
fmt.Printf("%d containers were stopped and removedn", len(resChan))
fmt.Println("Done")Now I just print them out, but maybe you want to send them to Sentry, etc.
Mutex
A mutex is an atomic way of locking and unlocking areas in memory. It’s similar to row or table-level locks in databases. When something is locked by a goroutine it cannot be used by other routines until it’s unlocked.
I don’t use mutexes in the cleanup script, but I use them in the actual code of ReelCode. When you submit your solution is it executed in a Docker container. But it doesn’t create and start the container on the fly. It uses a container pool with pre-created containers. For each language, it creates N number of containers. So at any given moment, there are (let’s say) 10 containers with PHP8 images. Or 10 containers with node images. These containers have already created and started. They are ready to run your code.
This is what the ContainerPool struct looks like:
type ContainerPool struct {
containers map[string][]string
capacity int
mu sync.Mutex
}containers is a map with similar values:
{
"php": ["7e5e8938", "d49fb47e"],
"js": ["3be6edf7", "9d736c37"]
}Keys are programming languages, and values are arrays (slices, omg!) of container IDs.
There are two exported functions:
Get(lang *language.Language) (string, error)
PushBack(lang *language.Language, ID string) errorGet returns a container ID for the given language and PushBack puts the container ID back into the pool for the given language.
The container pool should be thread-safe. Each incoming HTTP request runs as a separate goroutine. What happens if lots of requests come in at the same time and let’s say 20 of them calls Get in a matter of microseconds? Maybe 3 of them get the same container ID. That is problematic because you submit your code but you’ll see the result of another user’s code. I mean, it’s a high-quality troll move, but still. And then, of course, PushBack is going to be called with the same container ID multiple times. And then when Get is called it’ll return the same container ID for multiple users even if there are no race conditions. Not having thread safety will result in very very weird bugs.
And then I start adding hotfixes in the PushBack function like this:
if slices.Contains(p.containers[lang.ID], ID) {
return fmt.Errorf("container ID is already in the pool: %s language: %s", ...)
}I feel like I’m a genius. Uniqueness is guaranteed! omg.
And then I start seeing error messages in Sentry like these:
container ID is already in the pool: 6bc41401 language: GolangAnd then what?
Spoiler alert: never, not in 100 years you’ll debug problems like these. The problem with concurrency-related bugs is that they are so glued to the exact moment, the exact setup, and the exact environment in which they occurred that you have no chance to replicate them.
So I deleted the Sentry entry, went to the production site, submitted a solution, and arrived at my conclusion: “well, it works now. It was some server-related problem the whole time”
If you use a mutex you can avoid all of that.
When you access something, lock your memory:
func (p *ContainerPool) Get(lang *language.Language) (string, error) {
p.mu.Lock()
defer p.mu.Unlock()
containers, ok := p.containers[lang.ID]
if !ok || len(containers) == 0 {
return p.createContainer(lang)
}
// ...
}This is a function receiver (something like a method on an object) on the ContainerPool struct. p is the instance we’re working with (similar to this in a classic OO language).
p lives in the memory and it has a memory address:
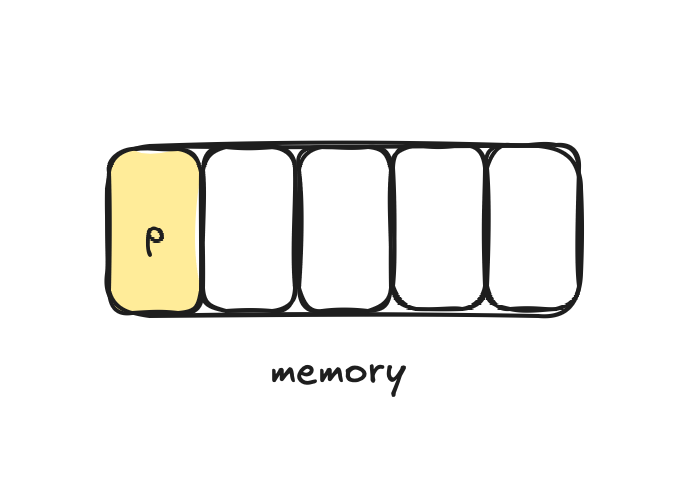
When you call
p.mu.Lock()This makes the yellow memory slot immutable for other goroutines. No one can modify it while the lock is acquired:
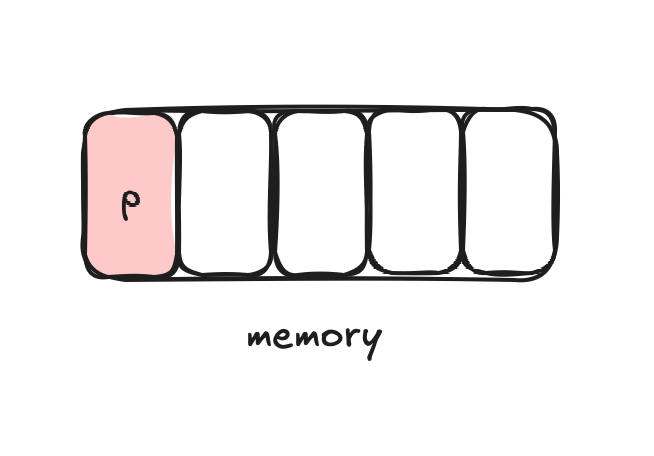
If another goroutine wants to modify p.containers (or any other field) while the lock is still acquired it needs to wait.
When you call:
p.mu.Unlock()You release the lock and the memory space of p can be modified again by other goroutines:
This is what a mutex is. It’s essential if you want to write thread-safe programs in Go.
<DON’T FORGET THE OUTRO AS LAST TIME>
Computer Science Simplified
 Donate To Address
Donate To Address Donate Via Wallets
Donate Via Wallets- Bitcoin
 Ethereum
Ethereum Monero
Monero

Donate Bitcoin to The Bitstream
Scan the QR code or copy the address below into your wallet to send some Bitcoin to The Bitstream
Donate Ethereum to The Bitstream
Scan the QR code or copy the address below into your wallet to send some Ethereum to The Bitstream
Donate Monero to The Bitstream
Scan the QR code or copy the address below into your wallet to send some Monero to The Bitstream
Donate Via Wallets
Select a wallet to accept donation in ETH BNB BUSD etc..
-
 MetaMask
MetaMask -
 Trust Wallet
Trust Wallet -
 Binance Wallet
Binance Wallet -
 WalletConnect
WalletConnect